前言
最近在重新設定 Mac 的 Terminal 時,發現現在關於 Zsh 和 iTerm2 的網路文章都太舊、很多指令已經不適用、安裝順序也很混亂,對於新手來說我覺得會很挫折,所以決定用最簡潔的方式把自己最近設定的流程記錄下來,目的是希望新手們也能輕鬆快速擁有一個美觀好用的 Terminal (幾年前我還是新手的時候,真的是設定到很崩潰…)
環境需求
- MacOS
- 已安裝 Homebrew
- 已安裝 git
安裝順序
請按照 1~5 步驟的順序,在 Terminal 中執行指令
1. 安裝 zsh
brew install zsh
2. 安裝 oh-my-zsh
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
3. 安裝 iTerm2
brew install iterm2
4. 安裝主題 Powerlevel10k
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
5. 設定主題
開啟 iTerm 並執行:
vi ~/.zshrc
- 按下
i切換成 insert 模式,往下拉會看到 ZSH_THEME,將它設定為ZSH_THEME="powerlevel10k/powerlevel10k",輸入:wq儲存並離開 - 執行指令:
exec $SHELL - 照著互動式的選擇題,依自己需求和喜好去輸入對應字母數字,最後就會自動套用到設定檔(若沒有跳出互動式設定或是想要再次調整,隨時可執行指令
p10k configure去做設定)
完成!
恭喜!你的 Terminal 已成功美化!

如果想要讓使用體驗更升級的話, 請往下繼續閱讀~
進階推薦:安裝 zsh 的 Plugins
可以選擇安裝自己需要的!
1. 安裝
- zsh-autosuggestions:自動補完常用指令
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
- zsh-syntax-highlighting:指令上色後更清楚易懂
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting
- zsh-z:快速前往常用或最近使用的資料夾
git clone https://github.com/agkozak/zsh-z $ZSH_CUSTOM/plugins/zsh-z
2. 設定 Plugins 並啟用
- 開啟設定檔
.zshrc
vi ~/.zshrc
- 按下
i切換成 insert 模式,往下拉看到 plugins 後在括號內加上 plugins 的名稱
我的範例如下(bindkey 那行是讓我可以用 tab 鍵自動補完指令)
# In ~/.zshrc
plugins=(git zsh-autosuggestions zsh-syntax-highlighting zsh-z)
bindkey '^I' autosuggest-accept
- 按下
:wq儲存檔案,並執行以下指令啟用設定exec $SHELL
如果 VS Code 的 Terminal 無法正常顯示圖示的話
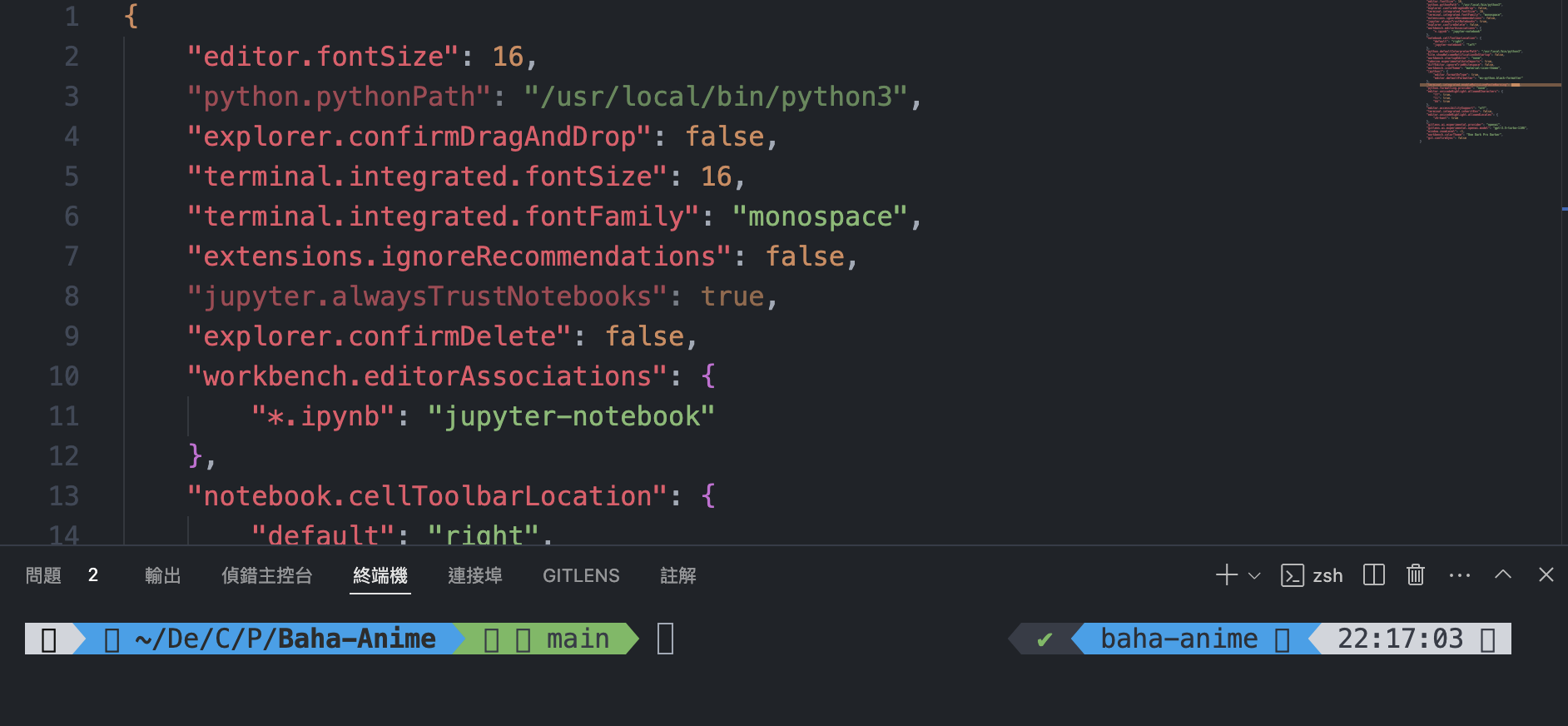
1.進入 VS Code > 點擊左下方的齒輪 > Settings
2. 點擊右上角的圖示,進入 JSON 檔

3. 新增下方設定到 settings.json ,並且記得儲存!
"terminal.integrated.fontFamily": "MesloLGS NF"

有任何問題都歡迎留言討論~







