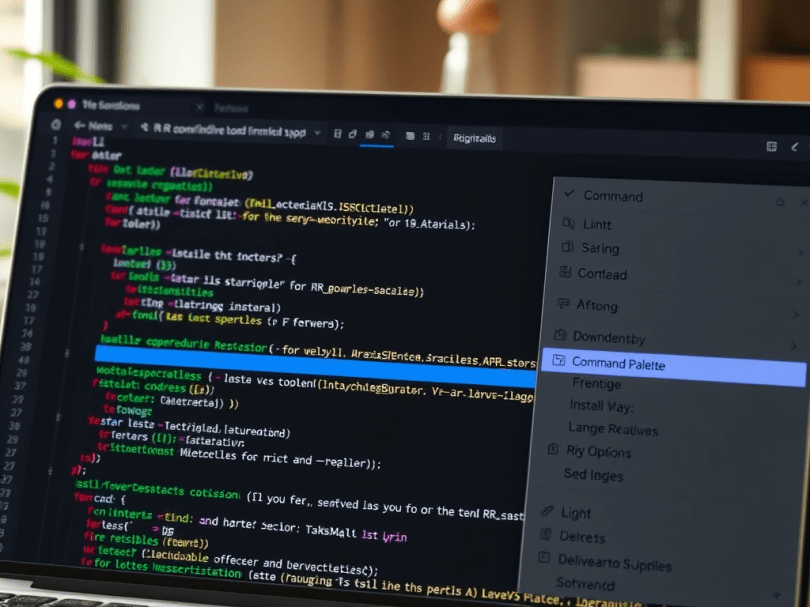
此篇文章記錄如何解決 R 程式碼在 VS Code 上會顯示一大堆波浪底線的問題(如下圖)

Step 1: 安裝 R extension
第一步一定要先安裝 VS Code 的 R 擴充套件,才會有排版建議和自動 Format 的功能
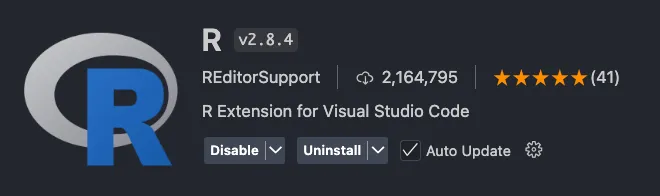
預設的 R Linter 是一行只能 80 字,很多程式碼底下會出現警告的波浪線條
Step 2: 新增 .lintr 檔案
- cmd + p (或 ctrl + p for Windows) 叫出 VS Code 的指令列
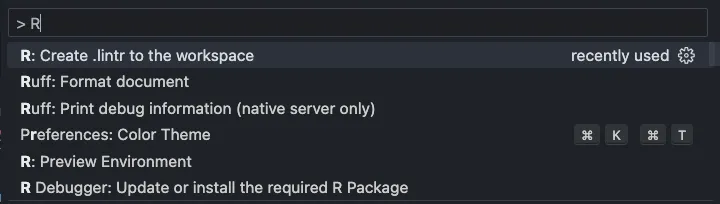
- 輸入
> R之後點擊「Create .lintr to the workspace」
(當然你也可選擇直接手動在根目錄新增檔案)
.lintr 檔案會出現在你的專案根目錄中
透過 R extension 預設內容如下,可以把全部先刪掉
linters: linters_with_defaults() # see vignette("lintr")
encoding: "UTF-8"









