- SQL 中的 UNION ALL 其實有陷阱?
- UNION ALL 實際上會造成什麼問題?
- BigQuery 新功能 – UNION ALL BY NAME
- 總結
- 補充資料 – CORRESPONDING 語法
- 參考資料
SQL 中的 UNION ALL 其實有陷阱?
在查詢結構化資料庫時,常會使用到一個 SQL 語法:UNION ALL,但其實這個語法背後有一個很大的坑,就是在合併資料時,UNION ALL 其實會按照 SELECT 的順序來合併 (Positional 特性) ,所以當欄位資料型態一樣時,資料就會無視欄位名稱被按照順序合併起來。
按照順序來合併資料是什麼意思呢?
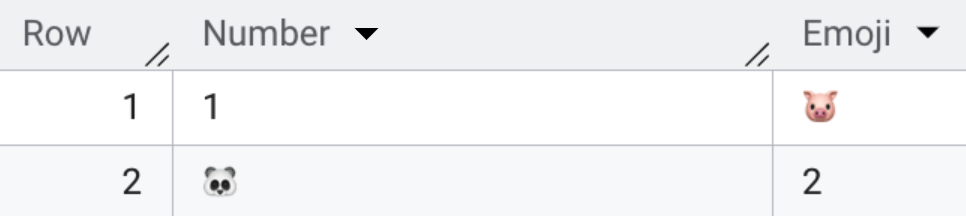
讓我們看一下範例
UNION ALL 實際上會造成什麼問題?
在這個範例中,我們想要讓名稱為 Number 和 Emoji 分別 UNION 在各自的欄位,由於這些值都是字串型態,所以 UNION ALL 是會成功執行的,但我們會發現結果並不是我們想要的那樣,因為我們的 SQL 中 SELECT 欄位的順序是錯的,UNION ALL 並不會自動幫我們依據欄位名稱去合併,這個問題除了 BigQuery 之外,其他資料庫像是 MySQL 或 PostgreSQL 也會有一樣的情況。