Meta (原 Facebook) 在 2022/09/29 發佈了最新的文字轉影片 AI,名稱叫做 Make-A-Video,我覺得算是一個滿值得研究的技術突破,也很好奇背後運作的原理,於是這次拜讀了他們發表的 Paper,大概了解一下整個 Text-to-Video (T2V) AI 的架構。
雖然說是文字轉影片,但其實主要的基底還是透過文字轉圖片的模型來實現,因為既然已經有模型可以將文字轉成圖片了,那就不用再造一個輪子去做文字轉影片的模型,畢竟影片也是建築在圖片之上,是由多個圖片所組成的。

過去技術上的瓶頸
研究中有提到,過去文字轉影片的技術一直遲遲無法有進展,有兩個主要原因
1. 影片資料不足
- 缺乏大規模的高品質且有標記文字的影片資料 (text-video pairs dataset)
- 這也是為什麼文字轉圖片技術雖然已經趨於成熟,但卻很難照同樣方式去產出影片的原因
2. 影片維度太高
- 圖片在做 embedding 時就已經有很高的維度,導致如果使用影片來訓練模型將會有極為複雜的維度問題
Make-A-Video 的技術突破點
- 能夠不用依賴有標記文字的影片 (text-video pairs) 就能透過文字產出影片
- 過去只能產出少數特定領域的影片,現在則可以產出更多元、更廣泛的影片了!
主要模型 Main models
能做到上述的突破,依靠的就是以下幾個模型的一連串效果
1. 文字轉圖片模型 (Text-to-Image, T2I)
- 主要就是培養模型對於文字和視覺上的對應能力
2. 影片模型
- 透過沒有標記文字的影片進行無監督式學習,主要是為了真實動作的訓練
3. 提升畫質的模型
- Frame Interpolation models(圖片插值模型)
- Spatiotemporal Super-Resolution models(解析度優化模型1)
- Spatial Super-Resolution models(解析度優化模型2)
關於各模型的詳細作用與相互關係,請繼續往下看架構部分

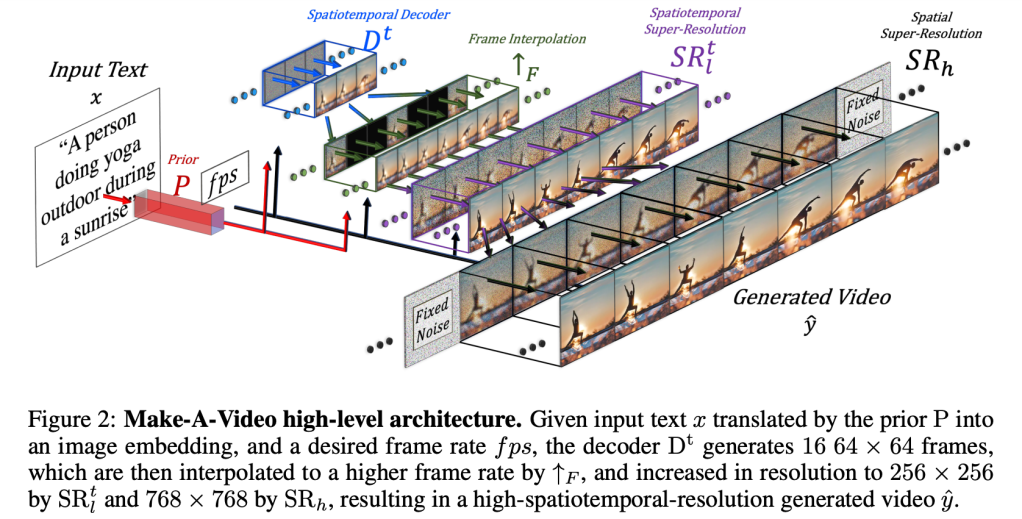
主要架構解析
以下按照先後順序簡單解析一下 Make-A-Video 的架構流程
1. Prior (P)
- 第一步是將文字做 tokenization 和 embedding,轉成 image embedding 和目標 frame rate(幀率,每秒影格數)
2. Decoder (Dt)
- 接著產出 16 張 64 × 64 的 RGB images (frames)
3. Frame Interpolation (↑F)
- 藉由插值法,將每幀中間再插入更多圖片,使 frame rate 更高
- 主要採用「每幀之間插入 5 張圖片」(frame skip 5) 的方式,將 16 frames 的影片增加到 76 frames ((16-1)×5+1)
- 用來提升流暢度,使其越接近影片
4. Spatiotemporal Super-Resolution (SRtl)
- 提升解析度到 256 × 256
5. Spatial Super-Resolution (SRh)
- 提升解析度到 768 × 768
6.最終產出一個短影片
- 圖解架構可以參考下圖
以上就是我閱讀 Make-A-Video 的 paper 後的整理,如果有誤或是有任何意見都歡迎提出!
參考資料
- Make-A-Video website: https://makeavideo.studio/
- Paper PDF: https://arxiv.org/pdf/2209.14792.pdf
