
前言
這幾年數據量增加速度越來越快,過去很多工具都標榜 Petabyte 等級,但今年開始有些公司的數據量已經達到 Exabyte (EB) 等級,例如 Uber 在近期的技術文章中就有提到他們 Hadoop 數據量已經超過 1 EB。
按照過去已經成熟普及的 Data Lake + Data Warehouse 體系,這麼大量的數據進到 Data Lake 後,再做處理儲存到 Data Warehouse 的流程,除了會造成非常大量的資料移動、資料處理、重複的數據產生之外,還需要維護複雜的大型 ETL Pipeline(Data Engineer 的惡夢…)
Data Lakehouse 的崛起
而這一兩年崛起的 Data Lakehouse 就是在解決這樣的問題,Data Lakehouse 通常會採用 Zero-copy + Open Table Format 的方式,讓 Data Lake 數據也兼具 Warehouse 的功能。
例如 Dashborad 使用的資料其實是直接取用自 Data Lake 的 Raw Data,等於直接省去了 Data Warehouse 這一層,這樣節省下來的成本會非常驚人!
目前 Data Lakehouse 主流框架
目前我看到 Data Lakehouse 主流的框架有三個
- Delta Lake(搭配 Spark)(Databricks 使用)
- Apache Hudi(Uber 使用)
- Apache Iceberg(Netflix, Apple, AWS 使用)
國外很多公司也都已經開始導入它們作為 Data Stack 的一環,如下圖
(圖片來源:Dremio – Comparison of Data Lake Table Formats (Apache Iceberg, Apache Hudi and Delta Lake))
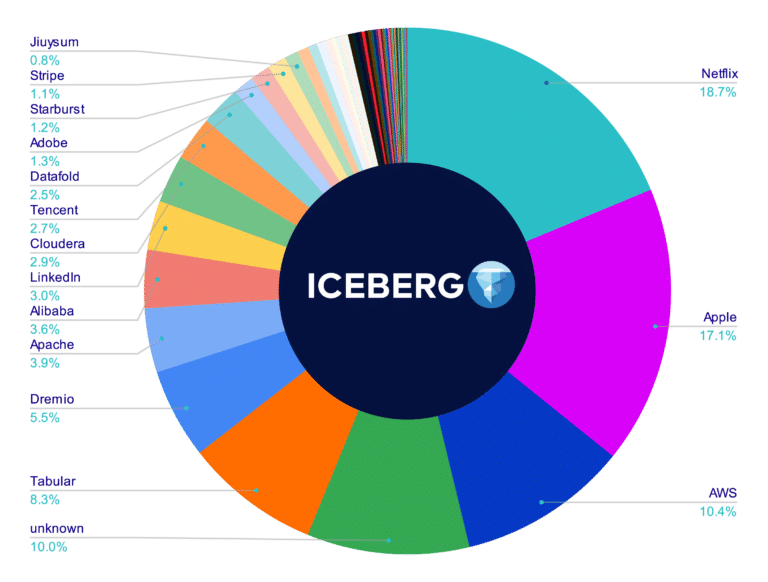
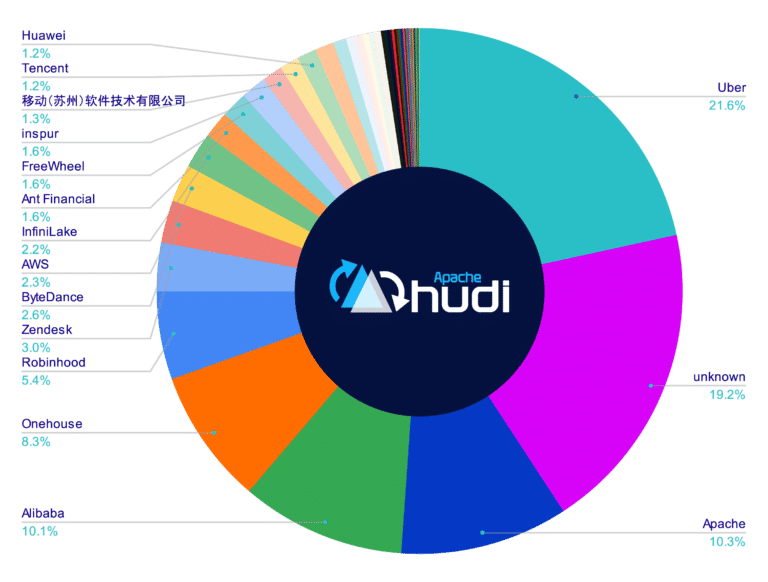
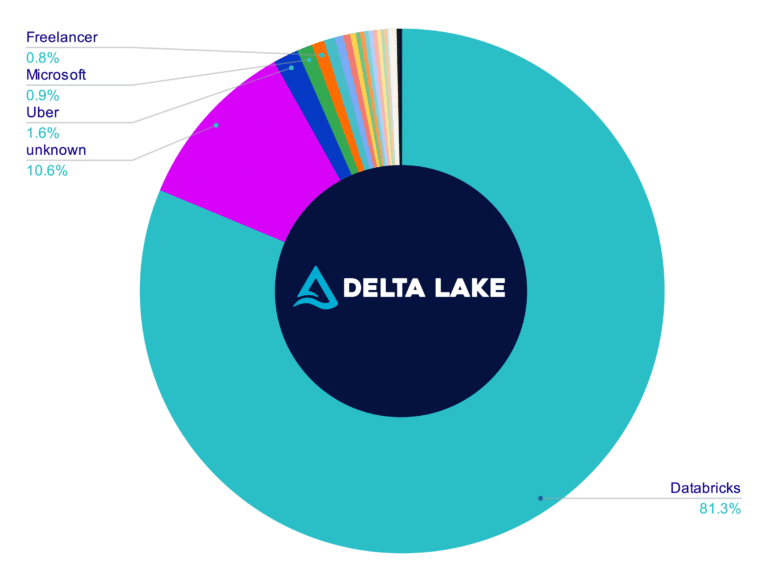
個人感想
台灣大部分公司可能都還是在 TB ~ PB 等級的數據量(或甚至根本還不重視數據),所以我覺得台灣應該還要個三到五年才有可能走到 Data Lakehouse 這步,雖然慢很多但好處就是我們可以等國外前輩們踩了很多坑之後再來導入(就像近期國外論壇也開始出現對於 Data Mesh 的各種抱怨XD),站在巨人的肩膀上總是比較輕鬆又看得遠!
我自己也是在這一兩年才好不容易摸熟了 Lake + Warehouse,現在又多出一個 Lakehouse,真的是永遠學不完啊…
2024.10.13 補充
近期認真讀了一下 Databricks, UC Berkeley, Stanford 共同撰寫的 Data Lakehouse 論文,也寫了一篇關於 數據架構演變的過程,以及不同代的數據架構有哪些優缺點的文章,對 Data Lakehouse 有興趣的讀者可以接著讀下方這篇最新文章。
參考資料
- Data Lakehouse 的概念是 Databricks 在 2020 年論文中提到的 Delta Lake:Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
- 2021 年 Databricks 又再次發表更詳細的 Data Lakehouse 架構:Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics

[…] 過去我也寫過一篇 關於 Data Lakehouse 的崛起與主流框架,有興趣的讀者也可以參考看看! […]
讚讚