相信很多人在做數據分析或資料清理的時候,都會使用 Google Colab、Jupyter Notebook 這些工具,其中 Colab 因為免安裝、易分享、可以跑 GPU 等等的特性,最近越來越多人在使用,老師們在線上課程教學上也很方便,但其實很多人不知道 Colab 有一些比較隱藏容易被忽略的實用功能,學會的話可以讓數據分析更加事半功倍唷!
Interactive Table (互動式表格)
原本的 Colab 表格就跟 Jupyter 表格是一樣的,如果要篩選或排序就要另外利用 Pandas 寫 sort_values、filter 或是 query 的語法,而我最近做爬蟲整理資料時發現,有個功能可以將原本的表格轉為互動式的,直接透過點按來做篩選、排序、分頁等等的效果。
這個功能預設是關閉的,有兩種方式可以轉換成互動式
- 執行下列程式碼開啟/關閉功能(建議)
- 在表格輸出後,點擊表格右上方的按鈕
轉換按鈕如下圖的紅框處,但這方法需要每次表格產出時都按一次,如果想要每個表格都直接產出互動式表格的話,還是建議執行上面的程式碼來一次搞定~
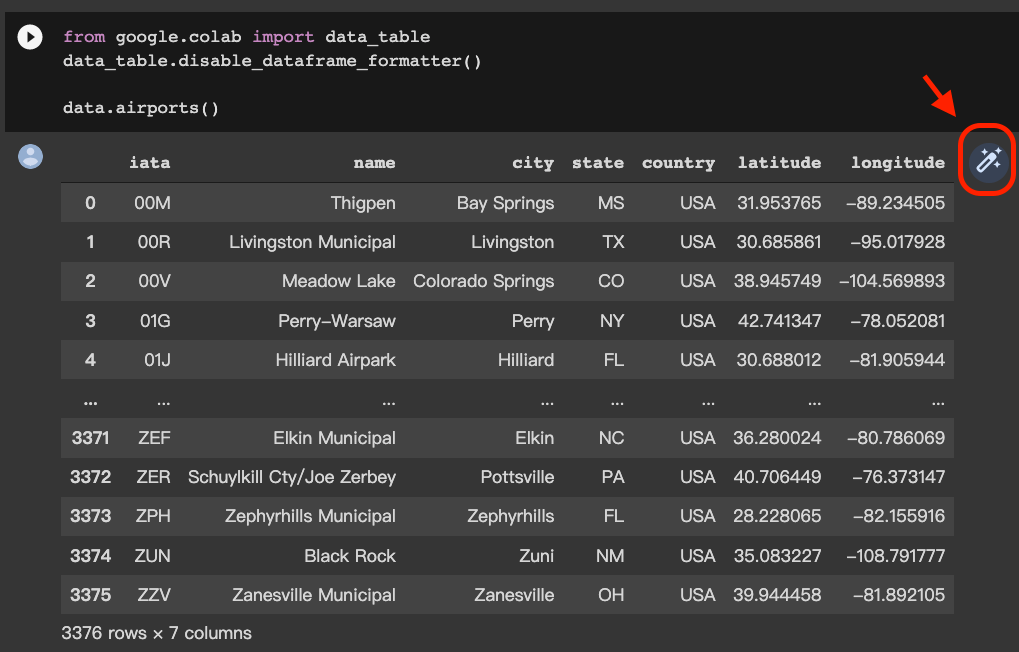
轉換後的互動式表格會長下方這樣