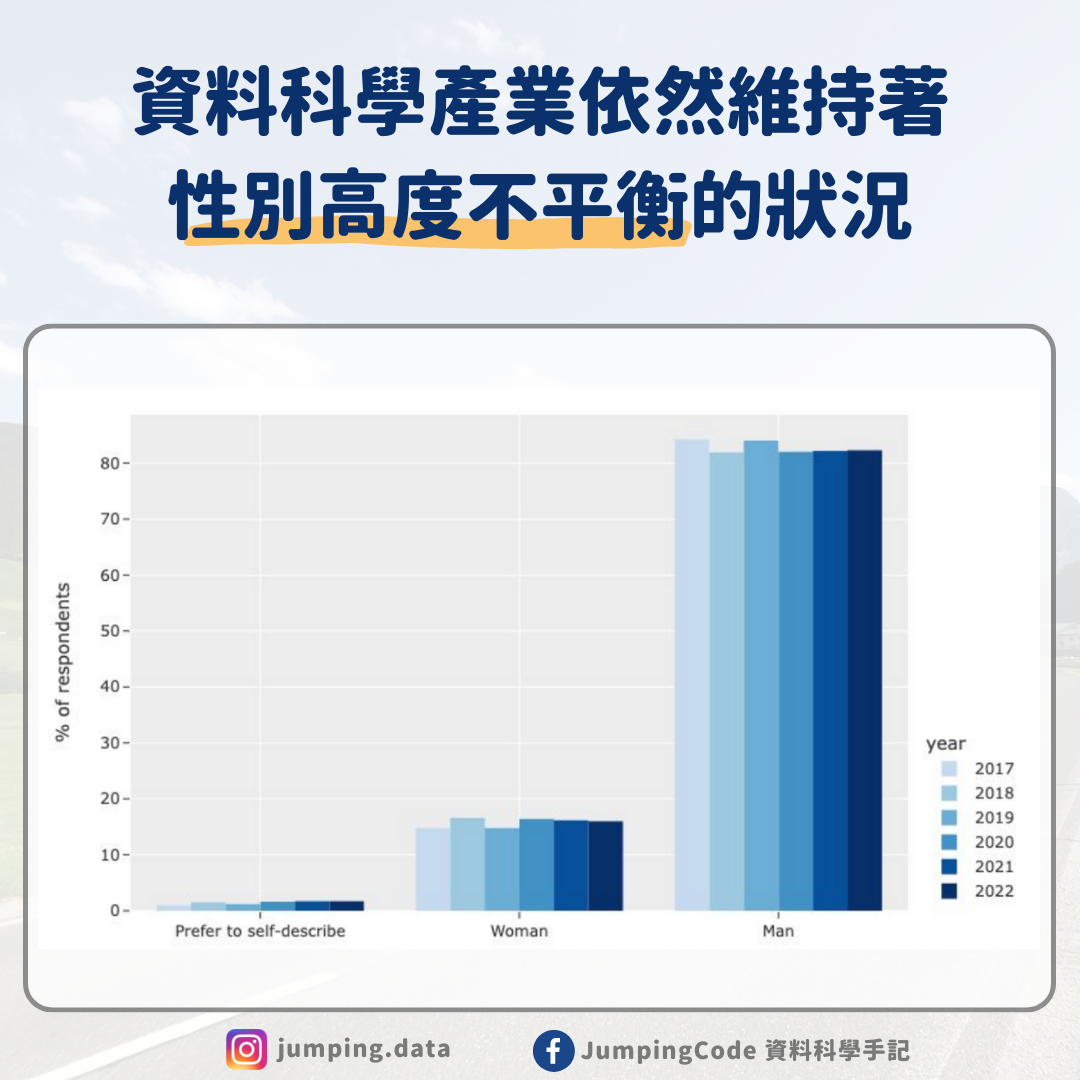
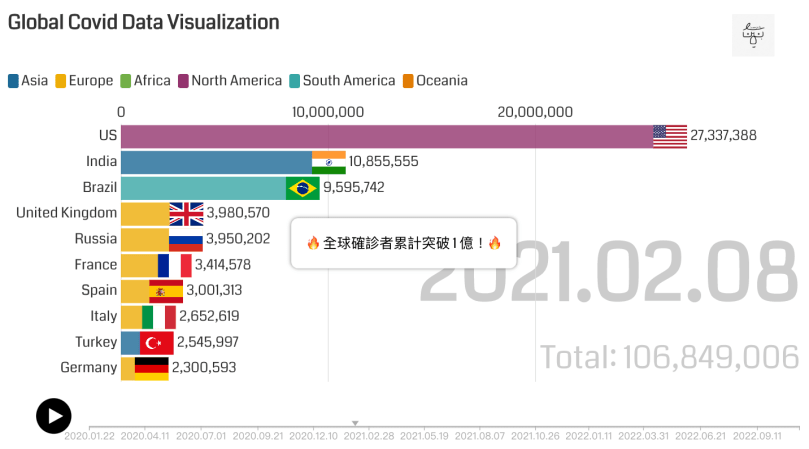
先自我介紹一下,作者 Jumping 我本人 2019 年以前從來沒碰過程式,透過自學資料科學相關課程,目前是有三年資料領域工作經驗的資料工程師 Data engineer,這篇文章記錄了我從自學到轉職過程的心路歷程,以及給同樣想要轉職的朋友的建議。
先聊聊我的背景
或許我跟大多數人一樣,在上大學前也完全不知道自己要念什麼科系,當時只想說「總之就是三類組,然後分數到哪就去哪」, 後來大學念了食品科學系,雖然後來也是有找到一點熱情,但畢業後仍然不知道自己要什麼,看到身邊不少朋友選擇繼續念碩士,我也憑著那一點熱情考了食品科學相關的研究所,所以在我的六年學生時期是完全沒有碰過程式,大部分都是生物和化學相關的課程和實驗。
當完兵出了社會,第一份工作理所當然的選擇進了食品業做研發,當時還常常被面試官問「為什麼你要做食品研發?」,老實講,我還真的回答不出來。
這種茫然困惑、不知道自己想要做什麼的狀態,一直持續到我出社會幾個月後,接觸程式語言時才開始產生變化。
接觸程式的過程
拿到工作的薪水後,我開始想該如何做投資上的運用,這時候我開始研究公司的財報、技術分析線圖等散戶會做的一些事,在查資料時發現很多人會使用 Python 自己寫爬蟲和畫線圖,於是我開始一點一點地學習怎麼樣寫 Python 語法,後來遇到有些股票網站資訊和圖表是需要付費訂閱才能觀看時,也試著自己按照那些付費圖表的邏輯去編寫程式,並嘗試視覺化出我心中所想的圖表。

(至於我自學的方式和課程,後續的文章會再做說明)
為何轉職?以及轉職時遇到的困難?
在這樣反覆學習和實作的過程中,漸漸發現自己對於寫程式收集及處理資料很感興趣,也很享受把想法和創意透過程式作品實踐出來的過程和成就感,於是就開始思考自己是否有機會轉職做一位工程師,而當時會想轉職很大的原因是:
- 覺得大數據是未來趨勢,所有公司將來都會需要數據來輔助決策,因此打算往數據方面的工程師發展
- 當然薪資待遇也很重要,我待的食品業算是傳產,薪資天花板比較低,如果轉職的話比較有發展空間
但同時也要思考許多實際上的困難
- 因為領域跨很多,所以要補的技術和知識實在太多
- 自己當時因為研究所 + 當兵 + 工作兩年已經滿 28 歲,要怎麼跟更年輕的肝競爭,還來得及轉嗎?
- 要離職專心自學嗎?我自己經濟狀況是否允許?

調適心態、面對挑戰
面對這些困難,我自己仍然做了轉職的決定,是因為有了心態上的調適,像是技術不足的部分我可以靠上課學習來補足,也選擇了在繼續工作的狀態下持續自學,讓我不用擔心經濟上的問題。

另外一個我覺得很重要的心態突破,就是評估了利弊之後,好好想一下「對自己來說,最糟的狀況是什麼?」,我自己的答案是「大不了我就是轉職失敗,然後回食品業工作」,所以其實現在轉職並不會有多糟的後果,也是因為這樣想,我才毅然決然繼續往轉職資料工作者的路前進。
你也想要轉職嗎?
當我過了兩三年,回顧我的轉職過程時,我覺得有幾點人生體悟,可以給想要轉職的朋友一些參考:
– 確立目標
凡事都需要一個清楚明確的目標,才能讓我們走在正確的路上!
– 動手實作
不論是在什麼領域,學習都不能只有輸入,最重要的還是輸出,學了之後一定要自己動手做,像是當時我自己的 Side Project 就幫助我找到工作。
– 放下「沉沒成本」
其實不會有所謂「真正準備好」的時候,何時開始都不嫌晚,最適合開始進行的時機就是「現在」,不要因為「沉沒成本」而委屈求全。我到現在還是很感謝當時的我所做的選擇,因為沒有當初的「捨」,就沒有現在的「得」!
– 列出恐懼與困難
把自己目前想得到的恐懼和困難都寫下來,如果自己還在為了轉職而卻步,想想這些困難是「知識技術」上的挑戰?還是其實是「勇氣」的挑戰呢?列出了所有的恐懼並面對它們,說不定會發現其實自己離目標沒有想像中的遠喔!

如果你正在為了要不要轉職而猶豫不決,希望我的這些經驗能幫助到你! 也歡迎把文章分享給正在轉職的朋友們!