Introducing Kaggle Models
Kaggle has released a newest addition: Kaggle Models.
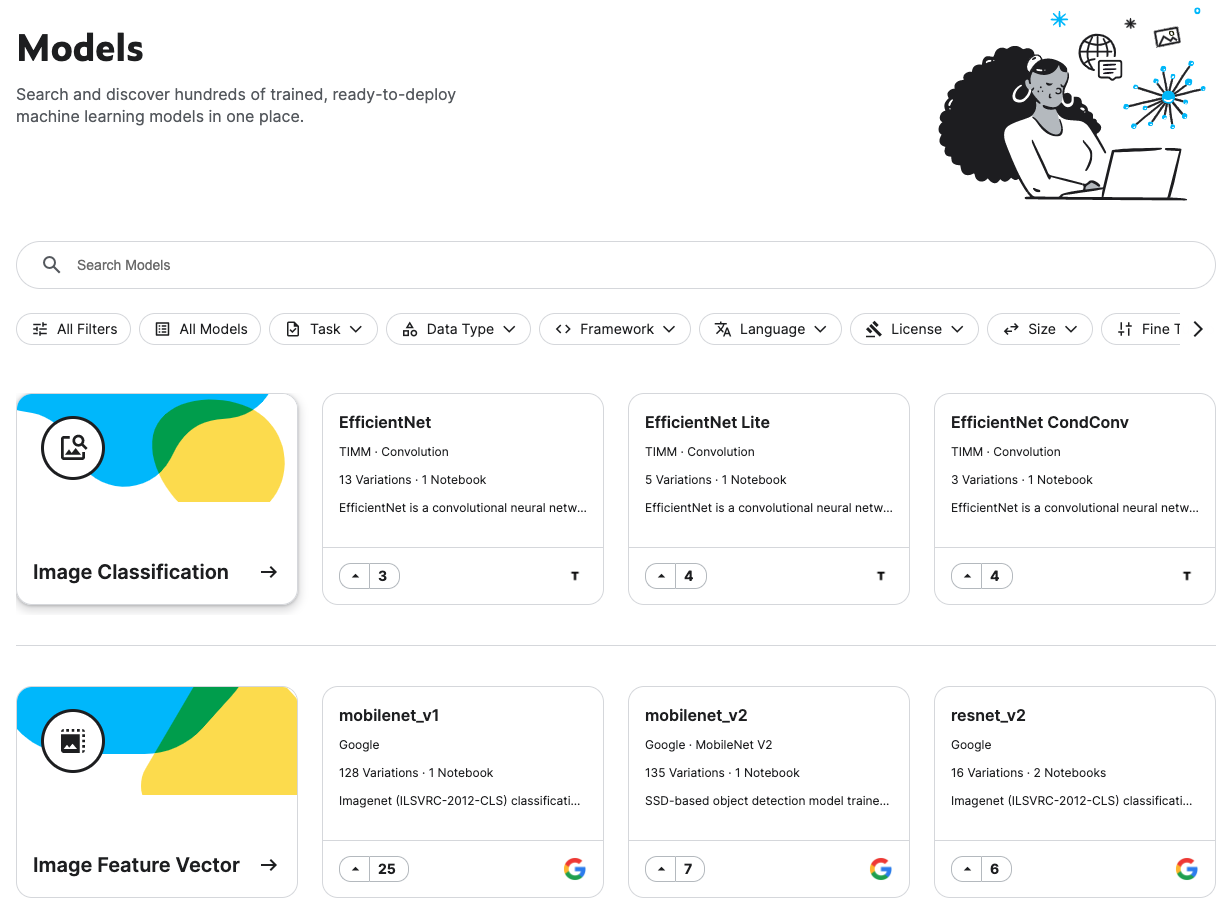
Kaggle Models is where we can discover and use pretrained models and is collaborated with TensorFlow Hub (tfhub.dev) to make a curated set of nearly 2,000 public Google, DeepMind and other models.
Models has a new entry in the left navigation alongside Datasets and Code.
In the Model page, it is organized by the machine learning task they perform (e.g., image classification, Object Detection or Text Classification), but can also apply filters for things like language, license or framework.
Using Models
To Use the models, we can either click “New Notebook” from the model page or use the “Add Model” UI in the notebook editor (similar to datasets).
Kaggle 新功能 Kaggle Models
Kaggle 最近發佈了最新的功能:Kaggle Models!
Kaggle Models 是 Kaggle 跟 TensorFlow Hub 合作,整合了將近 2,000 個 Google、DeepMind 等等的預訓練模型。
現在只要在 Kaggle 左側欄中,就可以看到多了 Models 這個選項(在 Datasets 和 Code 的中間),裡面預設是按照不同的機器學習用途 (Task) 來分類(像是 Image Classification、Object Detection, Text Classification),但也可以用過濾器篩選,像是語言、框架或 Licence。

Kaggle Models 的使用方法
如果想要使用這些模型,可以從 Models 頁面上點擊 “New Notebook”,或者點擊 notebook editor 中的 “Add Model”(跟使用資料集時差不多)。
參考資料
- Official announcement: https://www.kaggle.com/discussions/product-feedback/391200
- Kaggle Models: https://www.kaggle.com/models
歡迎追蹤我的 IG 和 Facebook
